一直都好奇网页的构建原理,今天我想试着揭开网页的面纱,得以窥见其中的美妙。
纵览网页的生命周期
首先,我会根据一个常见的场景来尝试描绘网页的奇妙之旅。
当我们在浏览器的地址栏输入网址时,浏览器就会尝试获取网页。
浏览器具体获取网页的过程,和我们输入的网址有紧密的关系。实际上,我们输入的网址,可以用一个专业名称来形容 - URL。URL 是 Uniform Resource Locator 的简写,意思是统一资源定位器。
分别解释下这三个单词的含义:
- Uniform(统一):全球有一个统一的网络 - Internet(互联网)。
- Resource(资源):通过网络传输的各种资源,网页、图片、视频、文件等。
- Locator(定位器):在网络上传输的资源都需要通过定位器来辨别彼此。
URL 为网络上传输的每一个资源提供一个唯一的标识符,也就是一个唯一的标签。
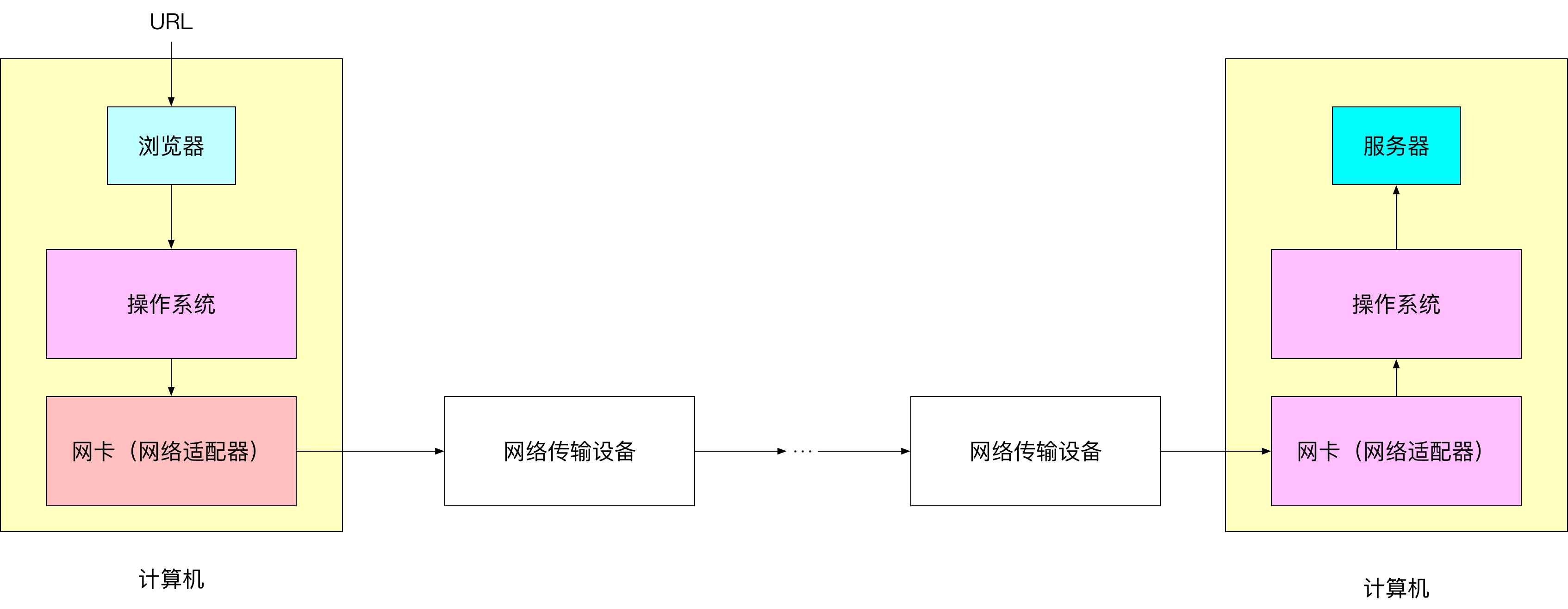
浏览器会将 URL 交给操作系统,操作系统会试图解析 URL,将解析结果发送给计算机上的网卡,网卡会传递消息给与其连接的路由器或其他网络设备。这些网络设备又会将消息传递给与其相邻的网络设备,直到传递给应该持有该资源的计算机,该计算机的操作系统会检测是否可以提供资源,若可以,通知相关程序准备好资源,然后再将资源发送给请求资源的计算机,当然,还得再次通过各种网络设备;若无法提供资源,也会发送一条消息给等待该资源的计算机,通知资源不存在。
当浏览器获取到网页后,就会开始解析网页内容,根据网页内容,可能继续请求资源,根据解析结果,生成最终的图像,发送给显卡。最终显卡会将图像绘制到显示屏上,我们就可以看见网页内容了。
最后再总结一下,实际以上过程可简单分成两部分:
- 获取另一台计算机提供的网页到本地计算机上
- 将本地计算机上的网页渲染到计算机显示屏上
网络资源的传输
我们常见的网页实际上可能包含了多个资源,这些资源一般存放在另一台计算机上,或者由另一台计算机动态生成。
由此,我们可以将资源划分为静态资源与动态资源。
也正是因为资源常常存在另一台计算机上,我们才需要使用网络从一台计算机上传输资源到另一台计算机上。网络就是为资源传输而设计的,它可以横跨地理位置的限制,连接世界各地的计算机,让通信变得愈加便利。为了让两台计算机之间能够传递数据,我们往往需要部署大量的网络设备,作为数据的中继站。这些网络设备种类繁多,用途不一,为了简化数据传输的复杂性,通过分层抽象的方法统一数据传输的方式。
现在实际使用比较广泛的是五层网络架构,自上而下分别是应用层、运输层、网络层、数据链路层和物理层。
- 应用层:实现应用程序之间的数据交换
- 运输层:保证数据传输的可靠性、实时性、完整性
- 网络层:实现网络节点的位置识别与查找
- 数据链路层:实现字节数据流的传输
- 物理层:描述网络设备之间的接口
在应用层,客户端与服务器使用 HTTP 协议交换数据,这里的客户端一般是浏览器,但不局限于浏览器。HTTP 协议依赖运输层的 TCP 协议实现数据的可靠运输,而 TCP 协议又依靠网络层的 IP 协议来查找其他计算机。
上面这三层协议都工作在操作系统上,而剩下的两层则一般位于网络适配器(网卡)中。
部署一个简单的 HTTP 服务器
接下来,我将编写一个简单的网页,并在本地计算机上启动一个 HTTP 服务器,托管该页面,然后从浏览器访问该网页。
首先,编写一个静态 HTML 文件,该文件描述网页的结构和内容,同时,还有一个 CSS 样式文件和一个 JavaScript 脚本文件。
|
CSS 文件简单地添加了一些样式信息。
|
JavaScript 文件中的脚本程序会获取网页中的内容。
|
以上就是一个简单网页需要的所有资源,总共 3 个静态资源,包括 HTML 文件、CSS 文件和 JavaScript 文件。
接下来,我将使用 Google Chrome 浏览器的一个扩展程序 Web Server for Chrome 来配置 HTTP 服务器,托管以上静态资源。
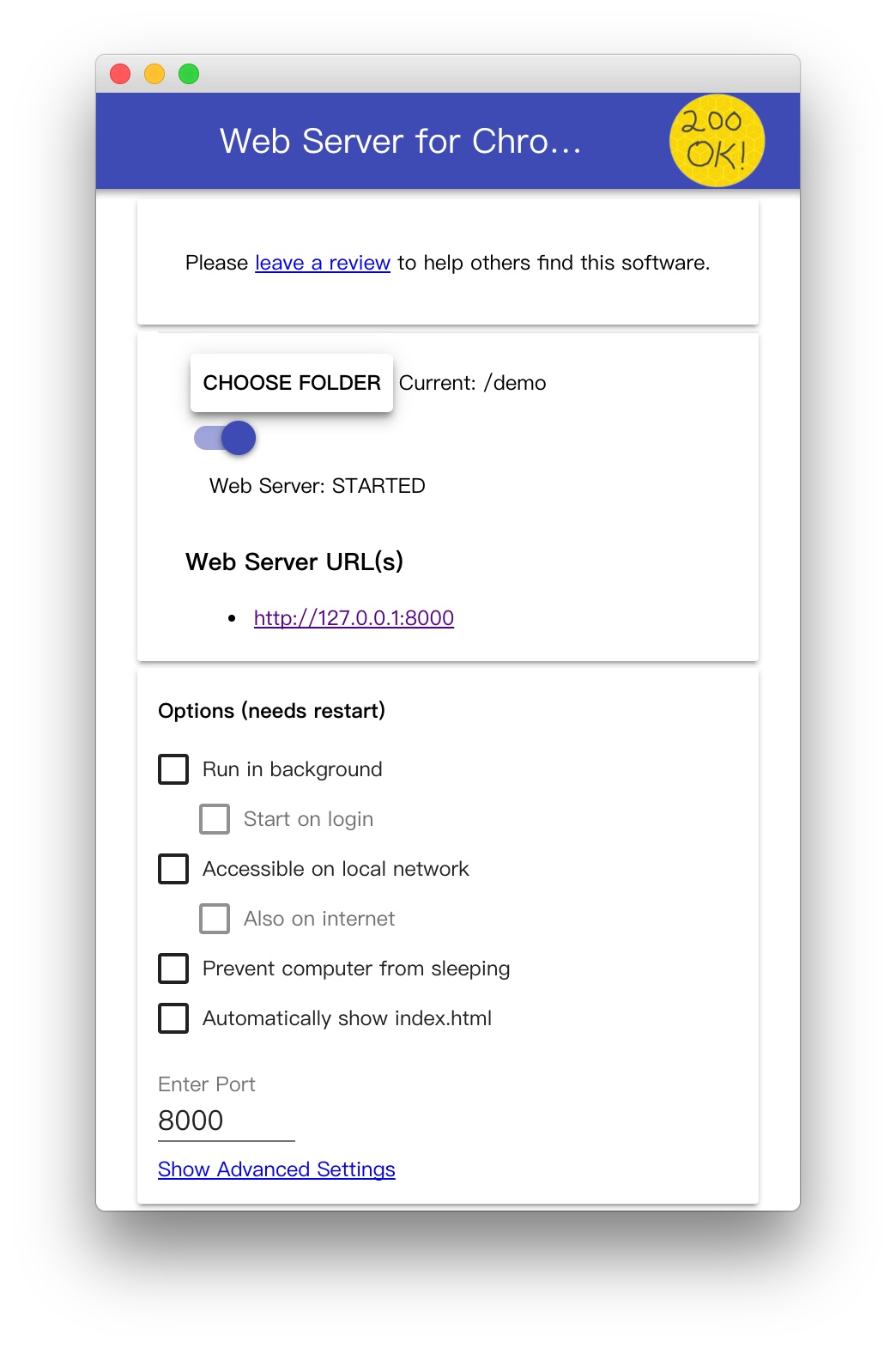
接下来,在 Google Chrome 浏览器的隐身模式下输入以下网址:
|
使用隐身模式,可以避免不必要的干扰,如扩展程序和缓存等。
既然我们已经成功访问了该静态页面,那么是时候来深入了解下浏览器是如何获取到静态资源。
捕获传输数据
Wireshark 是一个网络数据分析器,它可以追踪网络数据的传输,所以我将利用 Wireshark 来了解网络数据的传输细节。
访问本地的网络资源是一种特殊场景,一般用于开发者的本地测试。而 Wireshark 实际上是为监听网卡的网络数据而设计的,但本地访问本地的网络资源并不会通过网卡来获取资源。所以需要换种思路来监听本地的网络资源,在 Linux 和 Mac OS X 系统中允许 Wireshark 直接通过一个虚拟的网卡来访问本地资源,而 Windows 系统需要进行额外配置,这里就不展开讨论。
使用 Wireshark 分析 HTTP 与 TCP 协议交互的数据,因为 HTTP 协议依赖于 TCP 协议传输数据报文,所以,接下来只关注 TCP 协议的数据传输过程。
从打开网页到关闭网页,共需经过以下流程:
- 建立 TCP 连接
- 传递数据
- 关闭 TCP 连接
要建立 TCP 连接,需要经过三次握手。
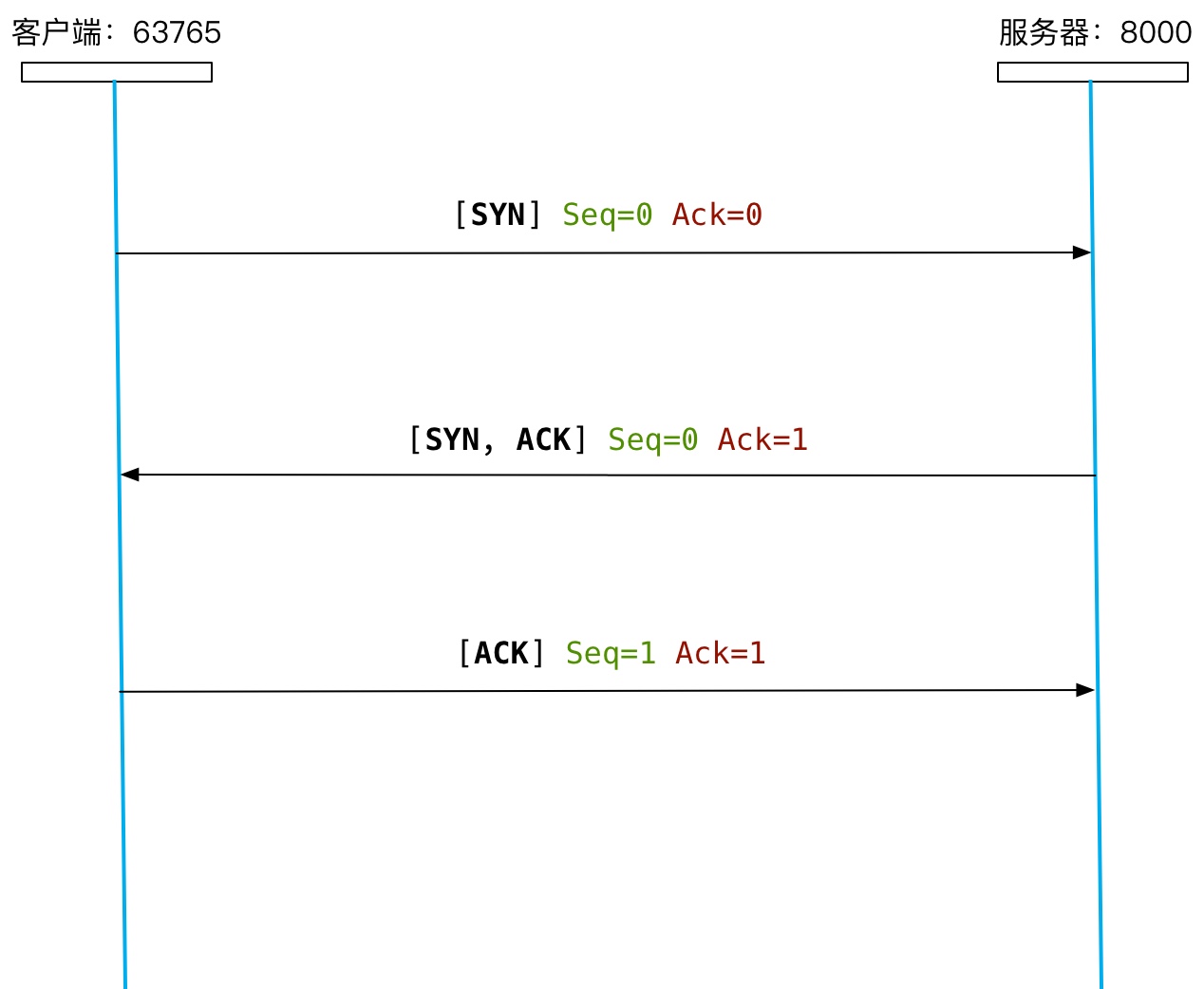
以下是一些关键点:
- TCP 连接由客户端发起
- SYN 标志着正在创建 TCP 连接
- ACK 标志着已收到对方之前发送的 Message(报文)
- Seq 为 TCP 报文的序列号
- Ack 为 TCP 报文的确认号
- 成功建立 TCP 连接后,客户端和服务器的 Seq 和 Ack 都为 1
成功建立 TCP 连接后,客户端和服务器就可以双向传递数据了。首先,客户端(浏览器)会发送以下 HTTP Request(请求)报文来获取 index.html。
|
HTTP 请求报文为 URL 编码方式编码文本,非二进制编码,换行使用
\r\n。
上面的 HTTP 报文共计有 428 个字符,包括空格和 \r\n。
在 URL 编码中,一个字符占一个字节,所有以上 HTTP 报文共占 428 个字节。
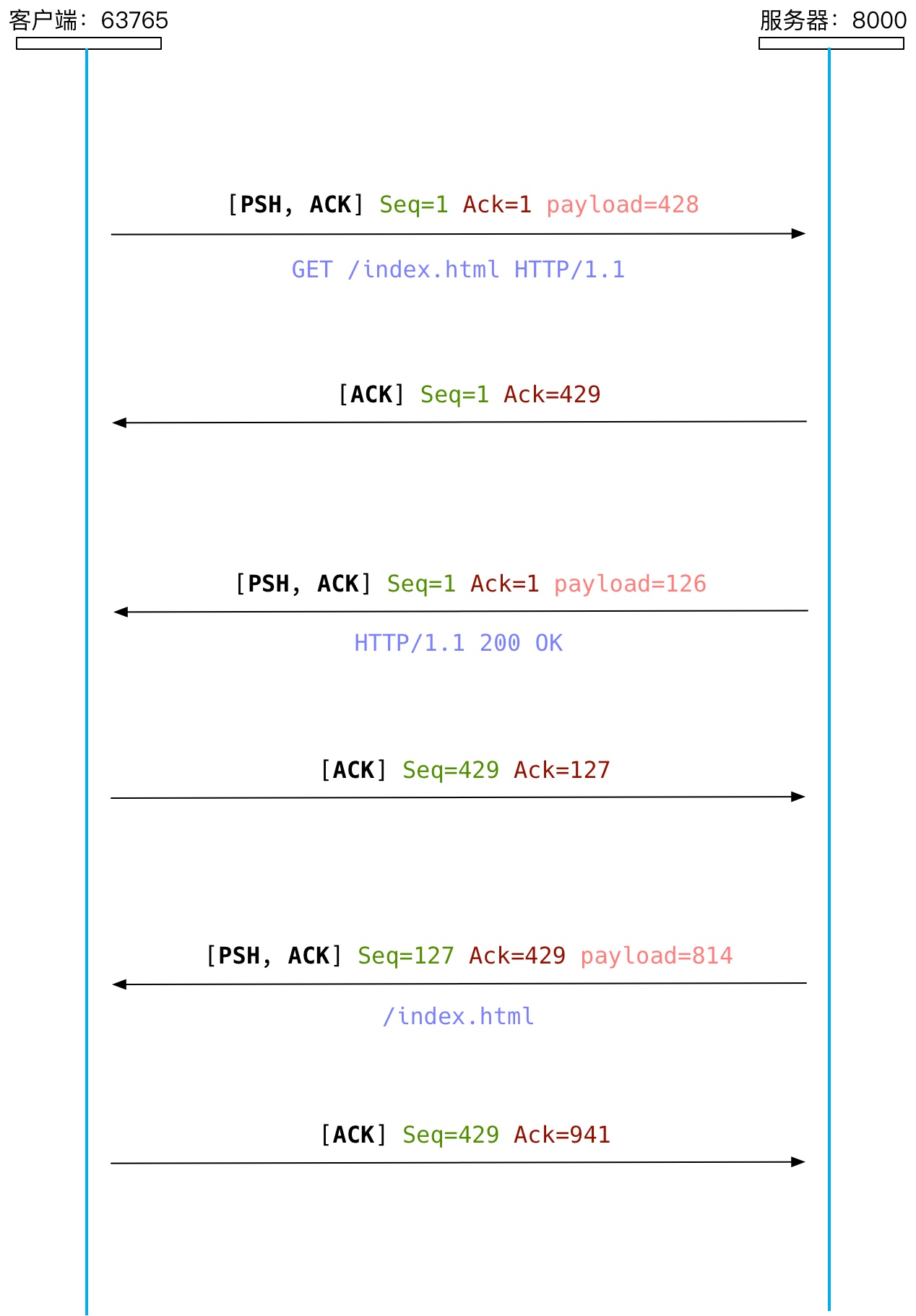
服务器接收到客户端发送的 HTTP 请求后,会将 HTTP Response(响应)分成 Response Header 和 Response Body 分两次发送给客户端。
其中,响应标头内容有 216 个字符:
|
响应体内容就是之间编写的 index.html 文件的内容,共计 814 字节,响应体长度同时记录在响应标头的 content-length 字段中。
浏览器获取 index.html 文件之后,就会解析 HTML 文件内容,再遇到以下标签时,又会发起一个新的 HTTP 请求。因为 TCP 连接还未关闭,此时会重用之前建立的 TCP 连接,省去了建立新的 TCP 连接的开销。
|
然后继续解析到以下标签,再次发起一个新的 HTTP 请求,此时 之前建立的 TCP 连接仍在获取 master.css,所以需要建立一个新的 TCP 连接来获取 index.js。
|
之后获取 master.css 和 index.js 的过程与 index.html 相似,就不再详细分析。
总结一下数据传输过程的关键点:
- PSH 标志当前报文携带数据
- Seq = 之前发送的所有报文的数据总长度 + 1
- Ack = 之前接收的所有报文的数据总长度 + 1
Keep-Alive
还有一点值得注意的是,之前发送的 HTTP 报文有一个特殊字段 connection。
|
该字段指示建立一个持久 HTTP 连接,这样可以重用 TCP 连接发起多个 HTTP 请求,如 index.html 和 master.css 就共用了同一个 TCP 连接。
为了维持一个持久 HTTP 连接,当 HTTP 请求完成后也不会关闭 TCP 连接,那么当一方出现故障,永远不会主动关闭 TCP 连接时,还一直维持 TCP 连接就不划算了,所以每隔一段时间,双方就得向对方发送一个 TCP 报文,检测对方的 TCP 连接是否还有效。
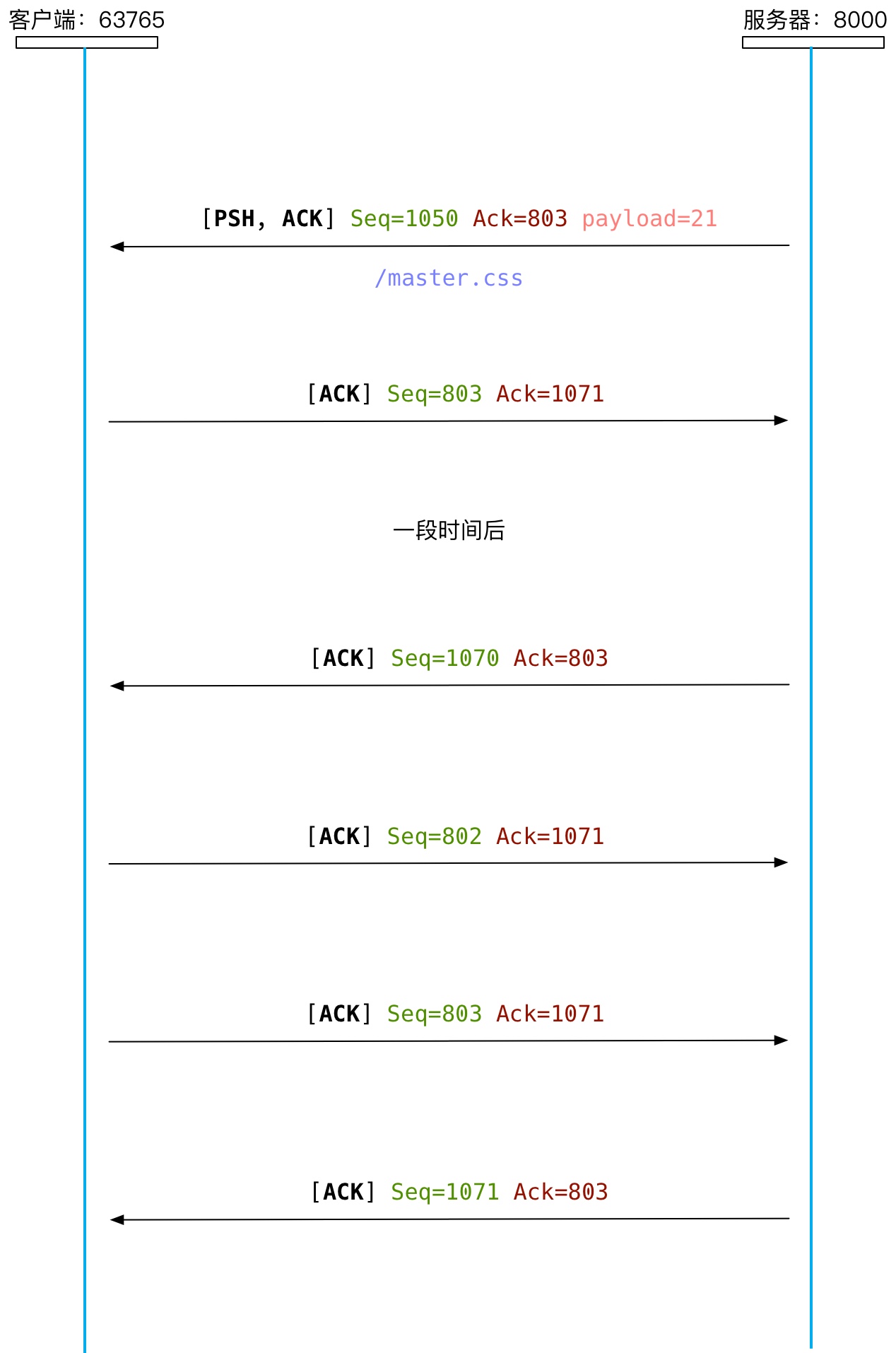
为了与一般的 TCP 报文区分开来,Keep-Aclive 报文的 Seq 会减去 1,若没有收到对方的确认报文,就会关闭该 TCP 连接。
总结一下要点:
- 客户端和服务器每隔一段时间就会向对方发送 Keep-Alive 报文,探测对方是否还在线
- 发送的 Keep-Alive 报文中的 Seq 要减去 1
- Keep-Alive 报文的 Seq 不用减 1
关闭 TCP 连接
当主动关闭网页时,将会关闭当前页面内建立的 TCP 连接,一个页面最多建立 6 个 TCP 连接。
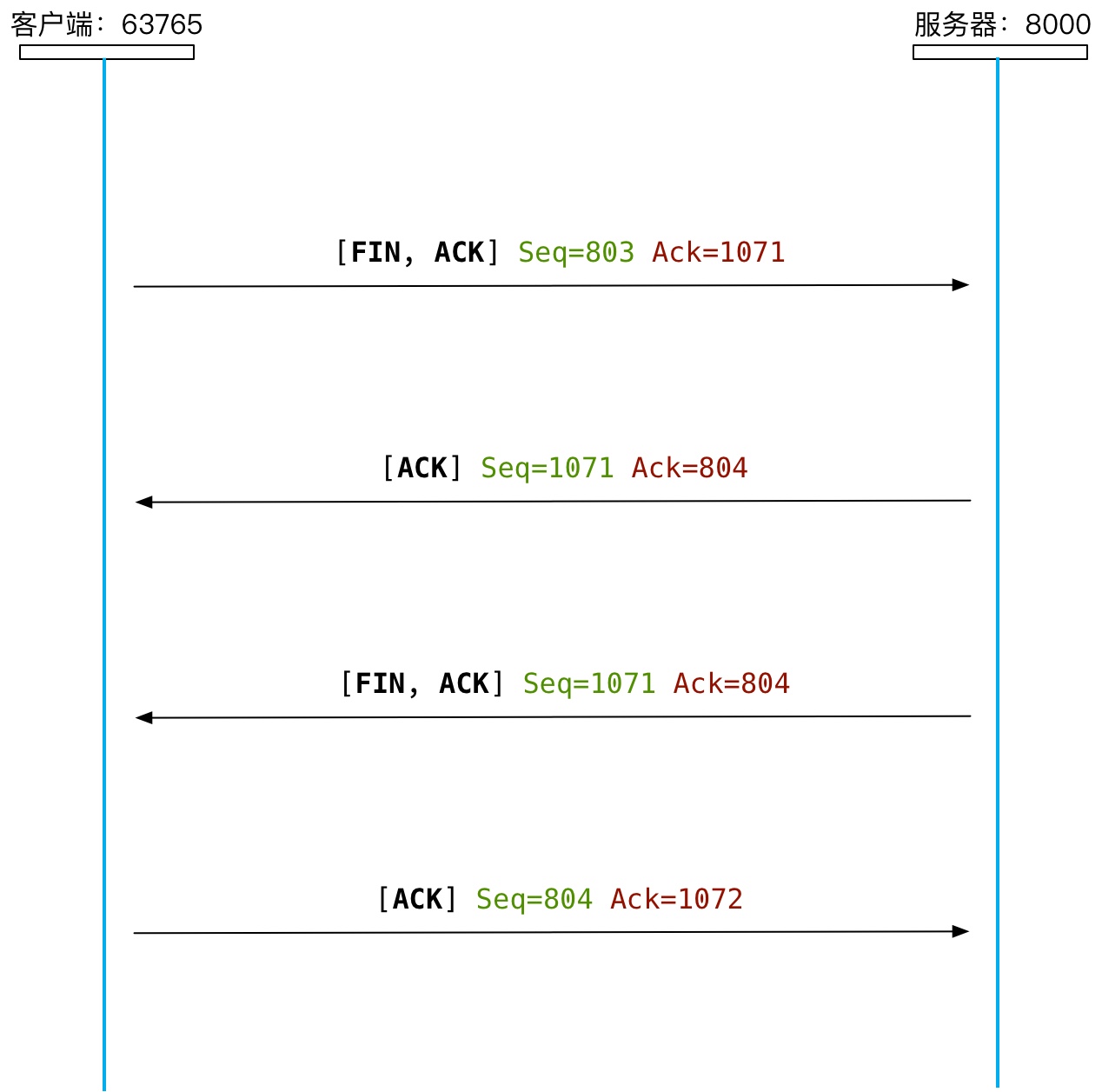
关闭 TCP 连接过程的要点:
- 客户端发起关闭 TCP 关闭请求
- 服务器确认客户端的关闭请求后,还得发送一次 TCP 关闭请求,并等待客户端确认
- FIN 标志想要关闭 TCP 连接
- 与 SYN 标志一致,FIN 标志也会导致 Seq 和 Ack 加 1
网页内容的渲染
上一节,已经介绍过了网页内容如何通过网络传输,现在我们可以来了解下浏览器如何处理网页内容,渲染到显示屏上。
从 HTML 、CSS 和 JavaScript 内容到最后的渲染到屏幕上的像素的过程,称为关键渲染路径。
关键渲染路径,英文名为 Critical Render Path。
关键渲染路径包括以下步骤:
- 解析 HTML 文档内容,构建 DOM
- 解析 HTML 内的样式表内容和 CSS 文档内容,构建 CSSOM
- 组合 DOM 和 CSSOM 构建 Render Tree(渲染树)
- 根据渲染树进行布局,计算可见节点的几何信息
- 将可视节点绘制到屏幕上
DOM(Document Object Model),中文翻译是文档对象模型。
CSSOM(Cascading Style Sheets Object Model),中文翻译是层叠样式表对象模型。
构建 DOM
浏览器构建 DOM 的过程:
- 解码字节:浏览器通过 TCP 协议获取到
index.html的字节表示形式,然后根据文件的指定编码(例如 UTF-8)将字节序列解码成字符序列。 - 生成令牌:浏览器按 W3C HTML5 标准 将字符序列转换成各种 Token(令牌),例如
<html>、<body>和<p>等。每个 Token 都有其特殊的含义和一组规则。 - 词法分析:将 Token 转换为有特定属性和规则的对象,也就是 DOM 中的 Node(节点)。
- 构建 DOM:根据 HTML 标记的位置关系将上一步生成的对象作为 DOM 树(数据结构)的节点。
我就简单拿 Hello, World! 这几个字符的解码来展示如何从字节序列转换成字符序列。

第一栏为 16 进制表示的字节码,第二栏为使用 UTF-8 编码解码后的字符串。
之后,浏览器就可以通过匹配特定模式的字符串来生成令牌。比如,<html lang="en"> 生成一个令牌:html 开始标签,拥有属性 lang,</html> 则生成另一个令牌:html 结束标签。
生成的令牌会被转换成一个特定的对象,该对象具有特定的属性,并且会根据令牌流中令牌出现的位置,将该对象插入到 DOM 树中。
下面盗一张图来展示以上过程。
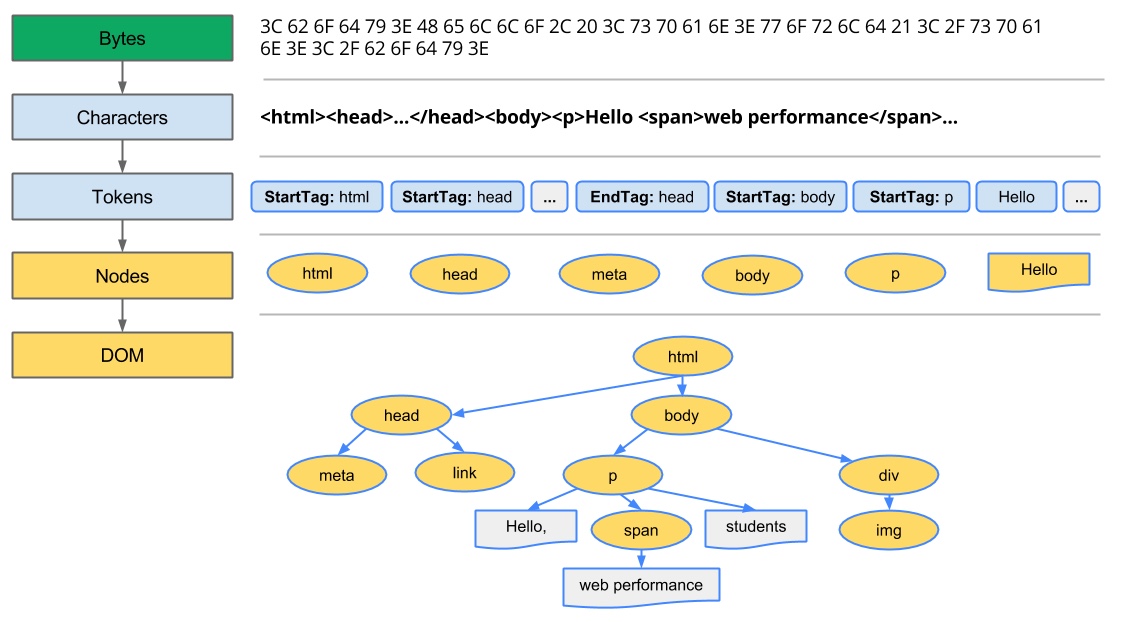
最终浏览器会构建一颗完整的 DOM 树,描述文档结构。
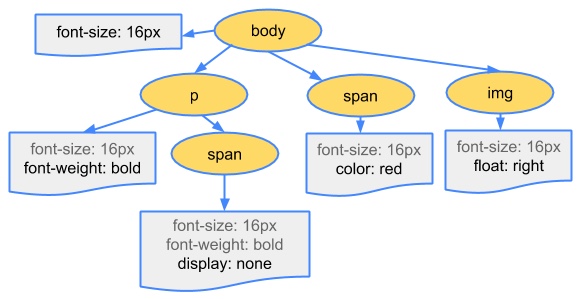
构建 CSSOM
构建 CSSOM 树的过程与构建 DOM 树的过程是一致的,只是解析的词法与最终表示的数据结构有所不同,最终构建的 CSSOM 树与下图类似。
构建渲染树
构建完成 DOM 和 CSSOM 后,还需要组合两者得到渲染树,渲染树只包含可见节点,即最终会显示在屏幕上的元素。
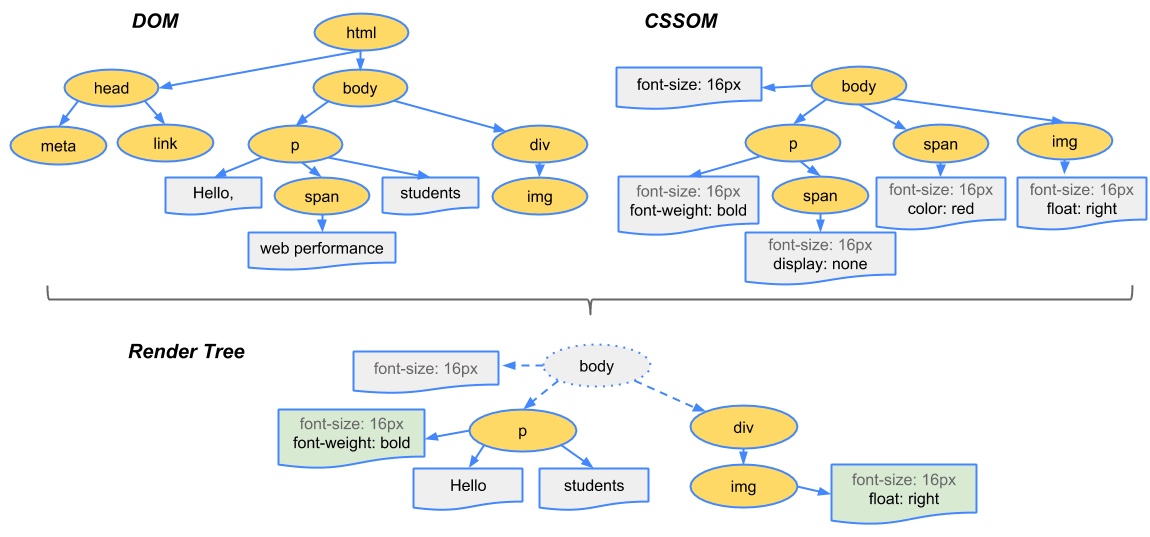
注意:CSS 样式规则
visibility: hidden是隐藏元素,但元素仍存在渲染树中,占据屏幕空间;而display: none则是设置元素不可见,即该元素不会出现在渲染树中,不会占据屏幕空间。
当渲染树构建完成后,浏览器就可以根据渲染树计算可见节点应该出现在屏幕上的位置和尺寸,绘制到屏幕上。
Layout
浏览器计算可见节点的位置与尺寸的过程,也被称为 Layout(布局),也称Autoflow(自动排列)。
元素的几何属性会影响布局:
- width(宽度)
- height(高度)
- margin (外边距)
- padding(内边距)
- border(边框)
- 其他几何属性
浏览器会参照显示设备的 viewport(视口)来计算元素在 viewport 中的显示位置。
布局和 CSS 的盒子模型有着紧密的关系。
Paint
既然我们已经知道了可见元素的样式和几何信息,那么就可以将该元素转换成屏幕上的实际像素,这一过程称为 Paint(绘制),也称为 Caster(栅格化)。
像素(Pixel)是显示设备的最小单位,每一个像素都包含自己的颜色和亮度,即我们常见的 RGBA。
RGB 分别代表红色(Red)、绿色(Green)和蓝色(Blue),A 则代表了透明度(Alpha),即亮度。
其实,像素是一个很容易混淆的概念,尤其在不同语境下,这是因为我们没有理清显示器原生像素、屏幕像素和 CSS 像素的关系。
就拿我目前使用的 2016 年推出的 MBP 13寸来说,内置 Retina 显示器的原生分辨率为 2560 x 1600,即共拥有 4096000 个物理像素。
但 macOS 系统中默认的屏幕分辨率为 1440 x 900,即 1296000 个屏幕像素,一个屏幕像素实际占据了 3.1604938272 个物理像素。这个数字看上去很怪异,如果我们将屏幕分辨率设置为 1280 x 800,即 1024000 个屏幕像素,那么一个屏幕像素实际占据了 4 个物理像素。
看上去,后面这种分辨率更合理一些,至于为什么默认使用 1440 x 900 的屏幕分辨率,我们之后再讨论,现在,我们想思考一下,为什么要将屏幕分辨率设置得比显示器的原生分辨率要小得多。
这是因为在 13 寸的显示器上,使用原生的 2560 x 1600 的分辨率将会导致屏幕上的所有显示项目缩小许多,这不利于日常使用,毕竟人眼长时间紧盯微小的事物还是很容易造成视觉疲劳的。所以,将屏幕分辨率缩小,就可以让屏幕上的项目显示为正常尺寸,并且更加细腻清晰。
为什么会更加细腻清晰?因为与同样 13 寸但原生分辨率与屏幕分辨率都为 1280 x 800 的显示器相比,原生分辨率为 2560 x 1600 且屏幕分辨率为 1280 x 800 的显示器显示同样尺寸的项目的空间里拥有 4 倍的像素个数,简单点说,就是像素更小,或者说,像素密度更大。
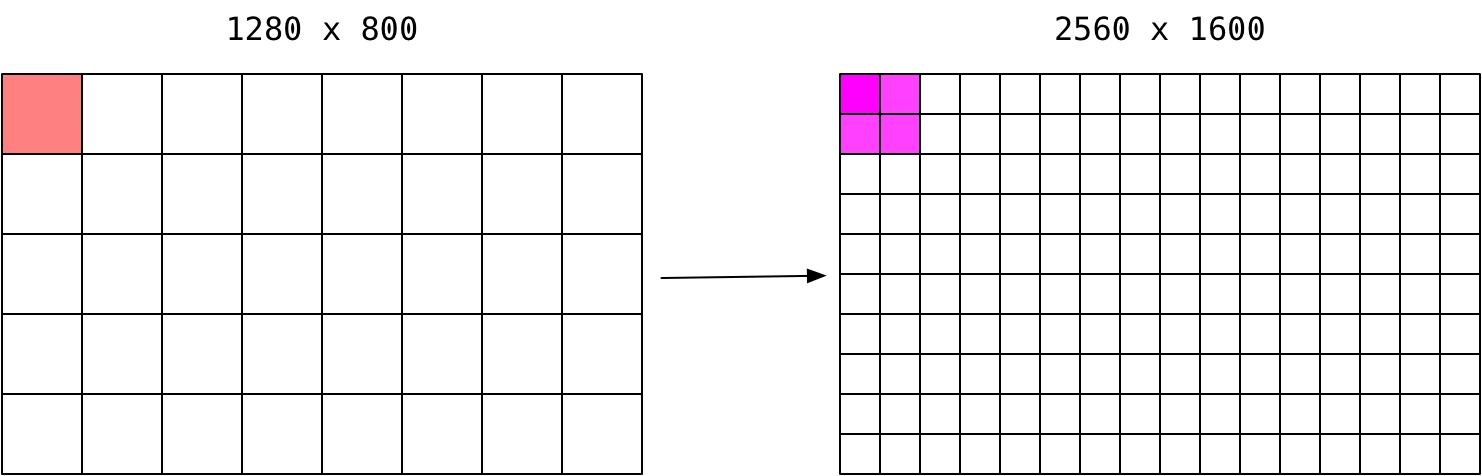
像素密度指的是单位面积内的像素个数,常用 DPI(Dots Per Inch) 或 PPI(Pixels Per Inch) 来表示。
现在我们了解了为什么存在屏幕分辨率与显示器分辨率不一致的原因了,那么来聊一聊为什么 2016 版的 MBP 13 寸的默认屏幕分辨率不是 1280 x 800,而是 1440 x 900。其实这是因为 MacBook Air 13 寸的分辨率为 1440 x 900,所以相同尺寸的屏幕下项目会更小一点,显示空间会更大一些,而如果 MacBook Pro 13 寸的默认屏幕分辨率(实际分辨率为 2560 x 1600)为 1280 x 800,那么就显得 MacBook Pro 13 寸的现实空间小了一些。为了不让消费者比较这两款产品时产生 MacBook Pro 13 寸屏幕看起来比较小的错觉,所以 Apple 把 MacBook Pro 13 寸的默认屏幕分辨率设定为 1440 x 900。
这是个有趣的小插曲,但不影响我们之后对 CSS 像素的讲解,因为 CSS 像素是浏览器用来绘制网页内容的一种抽象单位。
当网页的缩放比率为 100% 时,CSS 像素与屏幕像素是一致,即浏览器内 viewport 的分辨率应该与屏幕分辨率一致。当网页进行缩放后,CSS 像素可能比屏幕像素大,也可能比屏幕像素小,这取决于缩放比率。
实际上,你可能听说过设备像素,其实就是我之前谈到的屏幕像素,而不是显示器的物理像素。
了解完不同像素的区别之后,我们就能明白浏览器是按可见元素的 CSS 像素绘制到屏幕上的,CSS 像素乘以缩放比例得到实际渲染到屏幕的像素,屏幕像素(设备像素)乘以显示器缩放比例得到真正的物理像素。
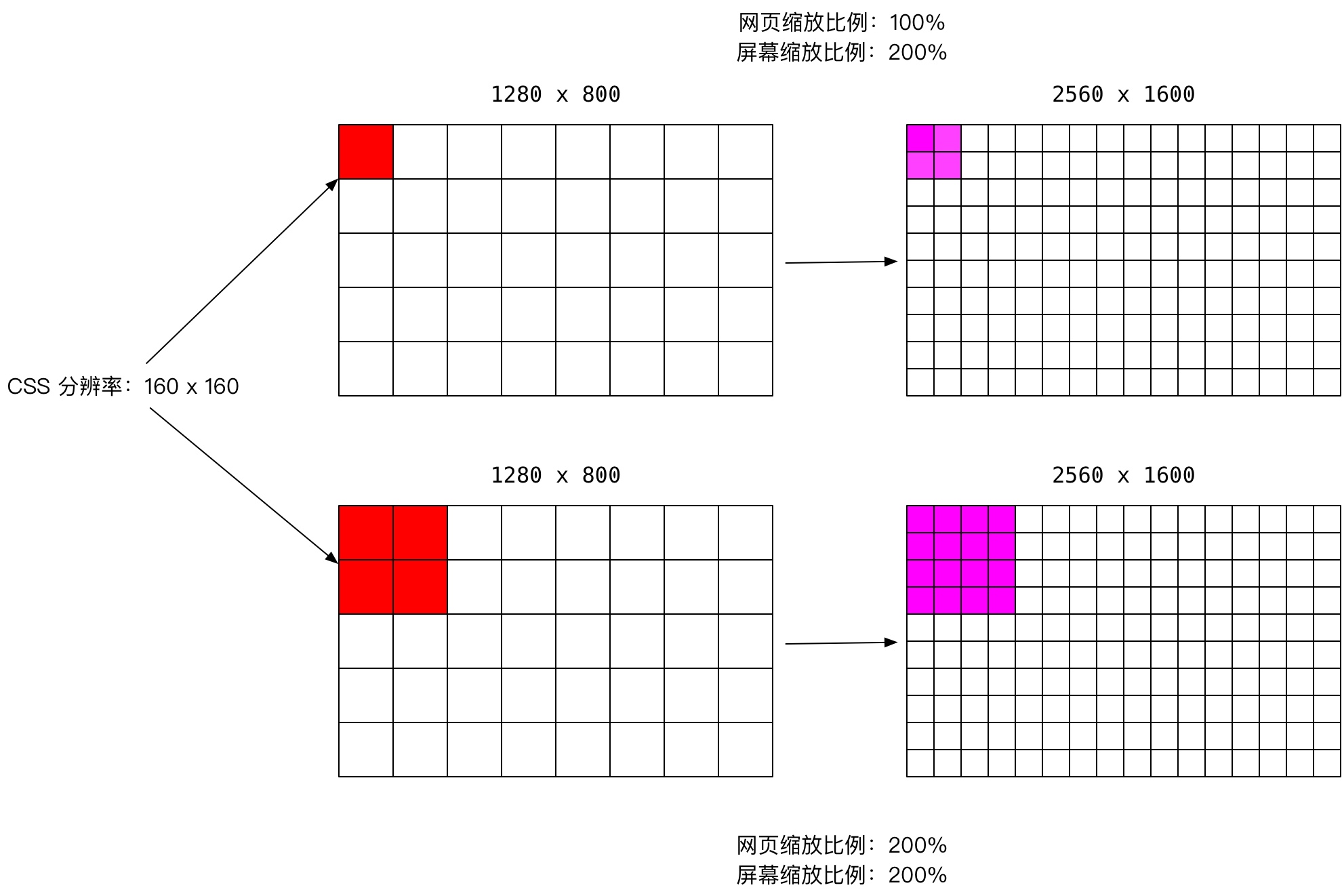
Composite
实际上,绘制的结果会保存到图层(Layer)上,如果存在多个图层,就要处理图层的重叠关系,最后将所有图层组合成一张位图,发送给 GPU(显卡),GPU 最终会将位图渲染到显示器的屏幕上。这种组合图层的过程,就称为 Composite(合成)。
为什么需要图层呢?这是为了节省计算开销,比如,一个使用 postion: fixed 的元素的位置会一直固定在屏幕上,当用户滚动页面时,就要重新渲染图像到屏幕上。如果只有一个图层,那么每次重新渲染都必须计算当前页面所有元素的布局信息,这样计算量就比较大,而且效率低下;但是如果把该固定元素放在另一个图层上,每次重新渲染时只需要将两个图层合成成一张图像即可,这样计算量就大大减少了,效率也就能提高。
浏览器处理网页的完整过程
最后,我们通过 Google Chrome 的性能分析工具来展现浏览器处理网页的完整流程。
打开 DevTools(开发者工具)中的 Performance(性能)标签,使用快捷键 ⌘ ⇧ E 启动性能分析并重载页面,当页面加载完成后,结束性能记录。
旧版本的 Google Chrome 中的性能分析在 Timeline(时间轴)标签。
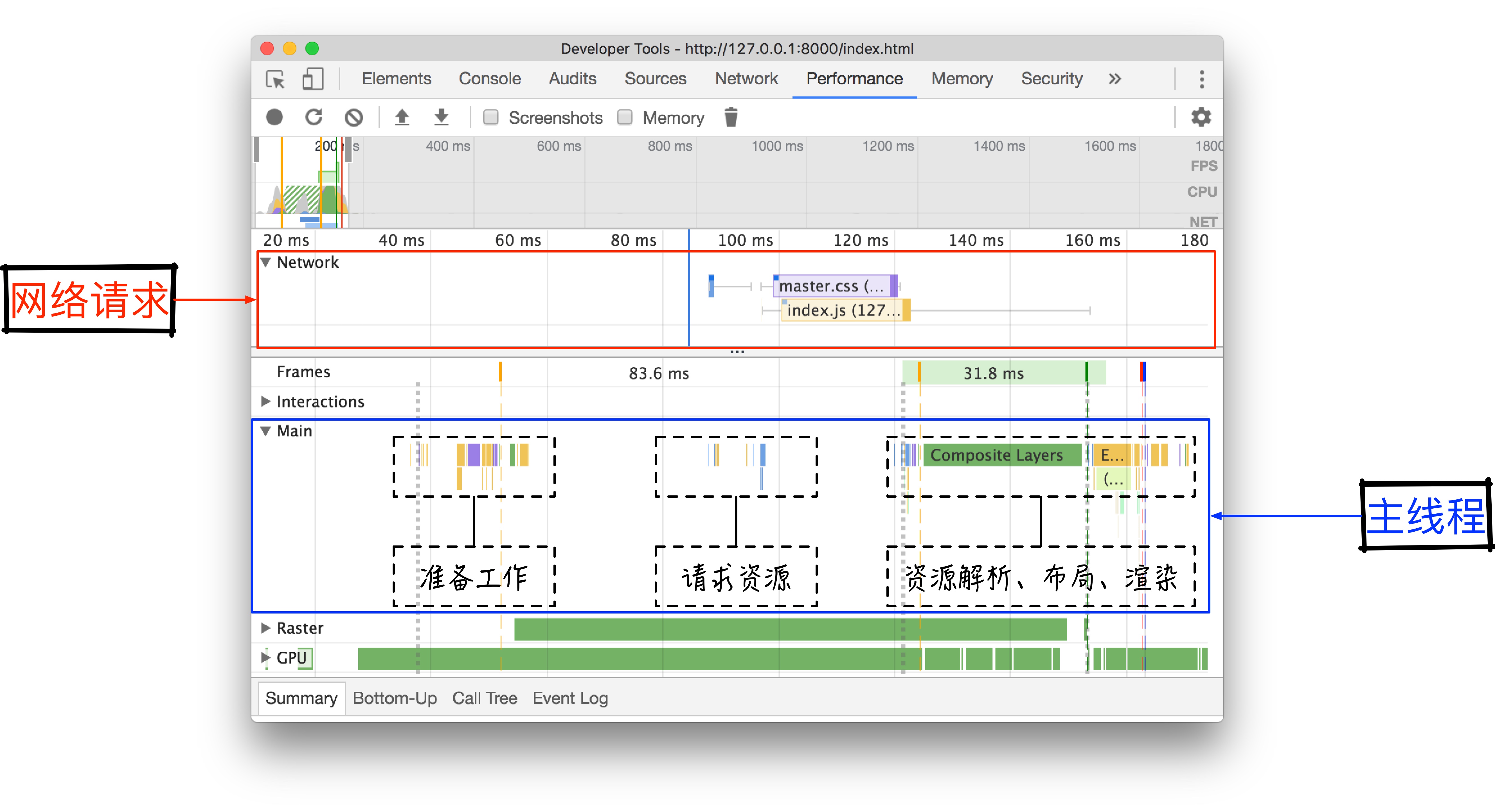
我们可以将整个时间轴分成三个阶段:准备工作、请求资源和资源处理。
我们将跳过「准备工作」阶段,直接分析「请求资源」阶段。
首先是请求资源 index.html:
- Send Request (index.html)
- Receive Response (index.html)
- Receive Data (index.html)
- Finish Loading (index.html)
上面的流程简化了触发的事件,因为此时我们并不能利用这些事件做点什么,所以就没有必要指出来。
然后解析 index.html:
- Parse HTML (index.html [1…15])
1.1 Send Request (master.css)
1.2 Send Request (index.js) - Receive Response (master.css)
- Receive Data (master.css)
- Finish Loading (master.css)
- Parse Stylesheet
- Evaluate Script (index.html:9)
6.1 Compile Script (index.html:9) - Parse HTML (index.html [16…32])
7.1 Evaluate Script (index.html:21)
7.1.1 Compile Script (index.html:21)
上面的解析 HTML 分成了两步完成,先解析 1-15 行,再解析 16-32 行,这是因为 <script>...</script> 中的内联脚本( 10-15 行)会阻断 HTML 的解析,优先执行脚本。
然而内联脚本并没有立即执行,这是因为要执行内联脚本,必须等待 CSSOM 构建完成,就必须等待 master.css 先加载完。
17 行我们定义的 <scirpt ... defer></script> 脚本并没有阻塞 HTML 文档解析,这是因为 defer 标注该 <script> 应该延迟加载与执行,不阻塞 HTML 文档解析和渲染。
DOM 和 CSSOM 都解析完成后,就可以构建渲染树:
- Recalculate Style
- Layout
- Recalculate Style
- Update Layer Tree
- Paint
- Composite Layers
渲染结束后,开始加载异步脚本 index.js 并执行。
总结
目前大多数 HTTP 服务器部署的 HTTP 协议版本是 HTTP/1.1,但 HTTP/2 因为支持更高效的双向数据流交互开始流行起来了,之后可能会专门写一篇博文介绍 HTTP/2。
在 HTTP/1.1 协议中,
- 默认一个网页只能同时打开 6 个 TCP 连接
- 默认启用持久 HTTP 连接
- 使用 TCP 协议作为底层传输协议
浏览器解析 HTML 页面:
- 解析内联样式和外部样式更新 CSSOM
- 解析内联脚本和外部脚本并执行
- 解析完 HTML 页面后构建 DOM
- 组合 DOM 和 CSSOM 生成渲染树
内联样式表和外部样式表不会阻塞 DOM 的构建,但会阻塞之后的 JavaScript 脚本的执行。
内联脚本和外部同步脚本会阻塞 DOM 的构建,但外部异步脚本不会阻塞 DOM 的构建。
浏览器渲染页面:
- 根据生成的渲染树,计算样式
- 布局
- 绘制
- 更新图层树
- 合成图层
- 渲染到屏幕