本文主要介绍了 CentOS 7 下安装 Hadoop 的流程,该流程只需轻微修改即可适用于其他类 Unix 操作系统。
Java
Hadoop 是基于 Java 编写的编程框架,所以必须先要有 Java 运行环境(JRE),同时为了之后的开发与调试需要,推荐安装 Java 开发工具包(JDK),JDK 中已包含了 JRE。
检查已安装版本
可以使用以下命令检查 Java 是否安装,以及安装的版本
查看 Java 版本$ java -version java version "1.7.0_141" OpenJDK Runtime Environment (rhel-2.6.10.1.el7_3-x86_64 u141-b02) OpenJDK 64-Bit Server VM (build 24.141-b02, mixed mode)
|
安装 Java
$ sudo yum install java-1.8.0-openjdk.x86_64 ... $ java -version openjdk version "1.8.0_131" OpenJDK Runtime Environment (build 1.8.0_131-b12) OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
|
Hadoop
下载二进制文件压缩包
接下来我们需要到 Hadoop 官网下载 Hadoop 二进制文件。

我们可以点击该链接进行下载,也可以复制该链接使用 wget 命令进行下载。
下载 Hadoop 2.8.0 二进制文件$ wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
|
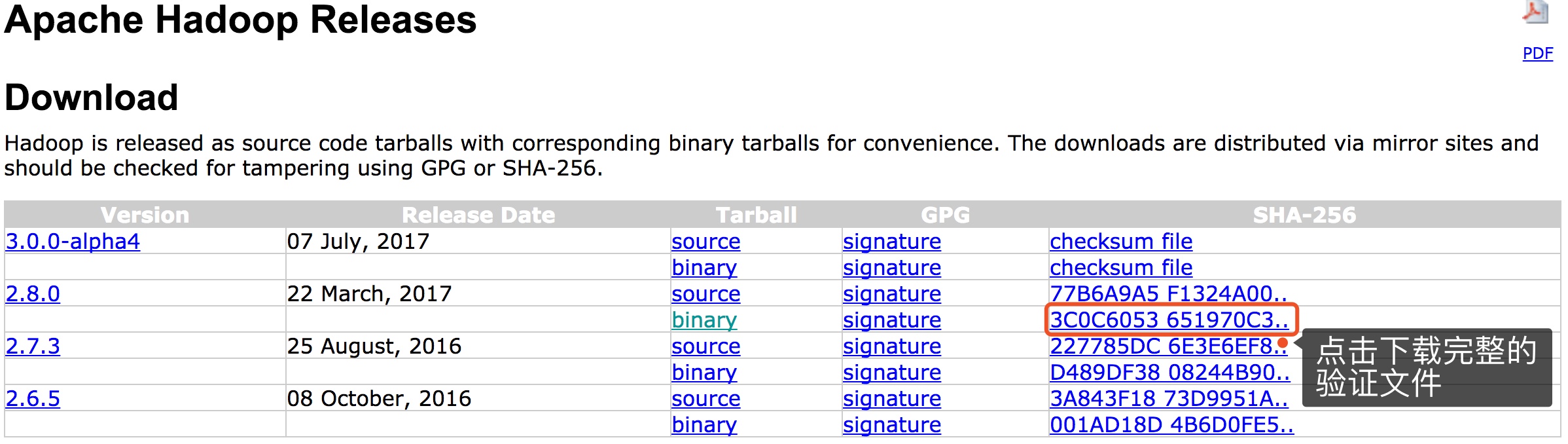
验证下载的文件未被修改
使用 SHA-256 快速验证
验证 hadoop-2.8.0.tar.gz$ shasum -a 256 hadoop-2.8.0.tar.gz 3c0c6053651970c3ce283c100ee3e4e257c7f2dd7d7f92c98c8b0a3a440c04a0 Applications/hadoop-2.8.0.tar.gz
|
你可以将输出结果与网页中的数字逐一比较,若相同说明该文件未被别人恶意修改。当然下图中只显示了一部分数字,你可以下载文件 hadoop-2.8.0.tar.gz.mds 查看完整的内容。
解压压缩包
解压二进制文件压缩包$ tar -xzvf hadoop-2.8.0.tar.gz
|
映射 Hadoop 主目录
创建 Hadoop 主目录的符号链接。
映射到link$ sudo ln -s /home/parallels/Applications/hadoop-2.8.0 /usr/local/hadoop
|
配置
JAVA_HOME
此时如果你直接运行 Hadoop 将会出错。
$ /usr/local/hadoop/bin/hadoop Error: JAVA_HOME is not set and could not be found.
|
所以我们就必须先找一下 java 的主目录,
查找 java 可执行程序的路径$ which java /usr/bin/java
|
再查看下该执行文件是否是链接,
使用 readlink 查找链接文件的链接目标$ readlink -f /usr/bin/java /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre/bin/java
|
-f 会顺着链接链找到最终的实际物理位置,我们实际要找的是 Java 安装目录(主目录),而不是可执行程序 java 的执行目录。
去掉 bin/java 后的路径才是我们要找的 Java 主目录/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre/
|
最后我们要设置环境变量 JAVA_HOME,可以有以下选项:
- 本次会话有效,关闭 shell 失效
- 本 shell 中有效,其他 shell 无效
- 本系统有效,所有 shell 都可以使用该环境变量
在这之前,我们先来讨论下两种设置方法。
静态设置
我们可以选择静态设置 JAVA_HOME ,这样下次更改 Java 版本的话需要重新设置新的 JAVA_HOME。
静态设置 JAVA_HOMEJAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre/
|
动态设置
或者,我们也可以选择使用 Shell 的命令展开式动态计算 JAVA_HOME 的值。
动态计算 JAVA_HOMEJAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
|
sed 用来截取正确的 JAVA_HOME。
现在我们再来讨论不同作用域的环境变量的配置。
Shell 变量
在 Shell 中设置 JAVA_HOME 的值,立即生效,但只在当前会话中有效,关闭 Shell 时即会失效。
Shell 中直接设置 JAVA_HOME$ export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
|
Shell 环境参数
第二种是将设置语句写入 Shell 的启动配置文件,这样每次 Shell 启动时都会设置 JAVA_HOME,不会立即生效,可以使用 source 在当前 shell 中执行脚本中的命令 。
将设置语句写入 Shell 的启动配置文件... export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") ...
|
假设你当前使用的 shell 为 bash
每种 Shell 的启动配置文件名都不相同,但它们都位于用户主目录下。比如,bash 的启动配置文件是 ~/.bashrc,zsh 的启动配置文件是 ~/.zshrc。
系统环境变量
第三种是写入到系统启动配置文件 /etc/profile,每次用户登录系统时都会执行该文件中的命令,需要重启生效。
/etc/profile... export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") ...
|
运行 Hadoop
当你配置好了 JAVA_HOME 之后,Hadoop 应该就能执行了。
成功执行结果$ /usr/local/hadoop/bin/hadoop Usage: hadoop [--config confdir] [COMMAND | CLASSNAME] CLASSNAME run the class named CLASSNAME or where COMMAND is one of: fs run a generic filesystem user client version print the version jar <jar> run a jar file note: please use "yarn jar" to launch YARN applications, not this command. checknative [-a|-h] check native hadoop and compression libraries availability distcp <srcurl> <desturl> copy file or directories recursively archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive classpath prints the class path needed to get the Hadoop jar and the required libraries credential interact with credential providers daemonlog get/set the log level for each daemon trace view and modify Hadoop tracing settings Most commands print help when invoked w/o parameters.
|
我们注意到每次执行 Hadoop 都必须输入一大串的路径名,其实我们可以再进行一些额外的配置工作简化对 Hadoop 命令的调用。当然,这是非必需的,可以根据自己的情况选择配置或不配置。
我们首先得知道,shell 是通过环境变量 PATH 来查找可执行命令的,如果我们要调用的可执行命令不在 PATH 中,就需要给出明确的可执行命令的路径(相对路径或绝对路径)。
这样,我们就可以采取两种策略,一种是在 PATH 中包含的目录里创建可执行命令的符号链接,一种是将可执行命令的路径添加到 PATH 中。
符号链接
$ sudo ln -s /home/parallels/Applications/hadoop-2.8.0/bin/hadoop /usr/bin/hadoop
|
添加到 PATH
既然还是设置环境变量,就存在之前讨论的作用域的问题,这个可以参考之前设置 JAVA_HOME 的流程。
设置 PATH$ export PATH=/home/parallels/Applications/hadoop-2.8.0/bin:$PATH
|
这里需要再提醒一下:我们是将可执行命令 hadoop 的执行目录,添加到 PATH 中,所以不要忘记加上原来的 PATH 的值。
推荐设置 PATH,因为 Hadoop 的一些脚本命令都是基于相对地址进行设置。